.jpg?width=400&name=RogerMasterClass-FeatureImage%20(1).jpg) One of the most common mantras in security awareness training is “Examine the URL to determine if it points to the legitimate vendor or not!”
One of the most common mantras in security awareness training is “Examine the URL to determine if it points to the legitimate vendor or not!”
It is great advice. Teach yourself and others how to read Internet uniform resource locator (URL) links so they can spot tricks from phishers trying to get them to visit bogus websites. Knowing how to spot the difference between microsoft.com and microsoft.com.biztalk.ru can save you a lot of misery and wasted hours.
So, even I say it (i.e., “Examine the URL”) all the time. I even have a one-hour webinar course called Combating Rogue URL Tricks. I wrote a related blog article, and you can even download a useful “12 Most Common Rogue URL Tricks” PDF here. I am all about everyone learning how to spot rogue URLs.
Most of the time, simply looking for and identifying the fully qualified domain name (e.g., microsoft.com) is enough to rule out what is and is not legitimate. Here is a screenshot from my Rogue URL presentation discussing how to recognize the referenced DNS domain name.

The vast majority of phishing attacks have a bogus (e.g., look-alike or sound-alike) domain name being used in the URL. So, a quick look can rule in or out whether an included URL points to a legitimate website or not.
But not always. As I cover in my Rogue URL webinar (and article and PDF), there are a multitude of tricks that phishers can use to trick people into clicking on a rogue URL. One of the most devious types is known as a redirection attack.
Redirection Attacks
With redirection attempts, the phish involves a legitimate domain name and website, but has found a flaw in the way that the host interprets typed in, additional variables. Let me explain more. When you type in or click on a URL (e.g., example.com), that URL uses DNS (domain name service) to convert the name you typed in or clicked on to take you to the IP address and service that is hosting content for that URL. You type in www.microsoft.com and you go to the server/service that the host responds to and host content for that provided URL. But if the provided URL has a question mark (?) after the domain name, then anything after the question mark is considered a “variable” and is passed back to the responding server/service for inspection and handling. Here is another slide from my Rogue URL presentation discussing URL variables.

Note: I will simplify server/services by just saying the more inclusive service.
The key is that anything after the first question mark in a URL is treated as a variable and multiple variables can be separated by an ampersand (&). Usually, variables are used by the hosting service to track users and their activities, but what the variable names are and what they are used for can be anything that the host service wants.
Note: I am simplifying this subject greatly to prevent this from being a 50-page ebook.
Part of the problem is what variables and their values are can be modified by anyone and presented for evaluation back to the host service. Now, normally this is not a problem. Normally, every hosting service only looks for particular variable names and values and will just ignore anything it does not understand. And you would think that anything it accepts and “understands” will not be dangerous to the service or anyone using it, but you would be wrong.
It turns out that lots of services (for decades) have allowed malformed variables to be submitted that can cause unintended, unauthorized actions. What those unauthorized directions are depends on the host and what the host allows and does because of the malformed variable values. In the simplest examples of variable abuse, perhaps a variable is used by a website to track users between clicks. Let’s say a variable called ‘user’ tracks users by number to their identity account, including credit card data. For example, perhaps ?user=456789 is a number that tracks to my identity. A hacker might try using ?user=456788 and see what happens. Perhaps it brings up another user’s session and credit card information. For this reason, websites, if they track users using URL variables, are supposed to make sure the user ID that might be used is seemingly as random as possible and unguessable – so an attack cannot just easily figure out what is and is not a valid user variable value and pull up that user’s account.
Some websites allow URLs to be created to allow other third parties to redirect users to another website. For example, perhaps the website wants to allow anyone arriving at their location to end up on the third party’s website after they visit their website. The “referring” URL could have a variable that indicates what the originating URL is. The host service sees it, handles the user, and when finished, sends the user back to that originating website. Let’s just make up a simple example of that scenario with a URL that looks something like this: www.example.com?referringURL=www.originalwebsite.com. The example website’s wish is simply to drop the user back off from the website they came from. The intent is pretty harmless. The fact that any URL could direct a person to a particular website and then get the user (actually their browser) redirected to any website of the URL-creator’s choice is known as “open redirection”.
A rogue hacker could use a phishing email that appears to be from a legitimate website, say example.com, but includes a malicious redirection URL that instead of bringing the user back to their original website, sends them to a new, malicious website (e.g., www.example.com?referringURL=www.maliciouswebsite.com). The hosting website never intended for the victim to be “dropped off” anywhere other than their originating website, but because they did not “parse” the variable safely enough, it just drops them off whenever the submitted URL (created by the attacker) says to drop the user off. This is a malicious redirection attack. They are not super common these days because website programmers are warned not to allow them to happen, but they do sneak by for days to months until someone reports the problem and the hosting website fixes the redirect issue. Hackers and phishers look for sites with URL redirects that can be used in phishing attacks.
Note: Malicious redirection and other similar tricks are covered here.
Example Real-World Redirection Attacks
Below are some real-world examples.
UPS.com Example
This recent example is the one that prompted me to write this article. My co-worker, Erich Kron, commented on it in that article. Essentially, the phisher sent an email claiming to be from United Postal Service (UPS), for a failed package delivery. We have all seen those. Pretty run of the mill.
But what they did in the email is include a URL that began with ups.com (see below).

This URL points to the real UPS.com website. So, if you just looked at that single data point, then it appears (and really) was taking you to ups.com. In fact, there is the screenshot (from the original article listed above) of what popped up when anyone clicked on the ups.com-containing link. That web page is not located on UPS.com.
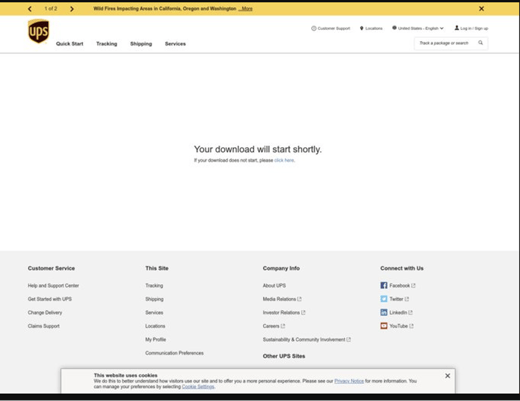
Source: Express
What the hacker did is use the real UPS.com website, but included an “onerror” redirect that tells the real UPS.com website where to redirect the user if the link originally directing them to the real UPS.com website contains an error. The phisher, of course, included something in the URL that creates an error condition. So, when the potential victim clicks on the supplied link, it takes them to the real UPS.com website, which then notices the “error” and then follows the redirect instructions supplied in the onerror variable. That part is actually very, very common for millions of websites. The difference is that instead of it pointing the tricked user to a real UPS.com web page (or the user’s originating web page if there was one), it points them to a malicious URL that is completely unaffiliated to UPS.com. The malicious website, however, looks like the real UPS.com web page (or looks closely enough that the tricked user does not greatly question it), that then asks the user to download a document. The document contains scripting, which launches malware.
The malicious redirect URL was Base64-encoded. The function(atob) is decoding the Base64 encoding back to its normal text (e.g., UTF-8) so that it can be evaluated by the user’s browser. The decoded URL in plaintext was: https://m.media-amazon[.]workers[.]dev/js, where the square brackets were added to prevent any readers from inadvertently clicking on the link and being taken by the rogue link to the rogue website and malicious JavaScript file. Overall, this example of a malicious redirect was as crafty as they come. It gets fixed by UPS.com more correctly evaluating the onerror variable so it cannot be used for malicious redirects.
Adobe.com Example
In this example, the phisher used the following URL: http://t-info[.]mail[.]adobe[.]com /r/?id=hc43f43t4a,afd67070,affc7349&p1=maliciouswebsite[.]com/r/?id=159593f159593159593,hde43e13b13,ecdfafef,ee5cfa06. This example is from: https://www.reddit.com/r/sysadmin/comments/d9ndnf/heres_a_phishing_url_to_give_you_nightmares/ (which is not a malicious link).
In this case, the phisher’s email is claiming something to do with the legitimate company Adobe. The p1 variable allowed a malicious redirect. So, the potential victim would be taken to the legit abobe.com website and then redirected to the website of the phisher’s choosing. Of course, they could also base64 encode the malicious website’s URL to hide the redirect.
Google Example
This example came from Microsoft. In this case, the phishers found an abusable redirect on the Russian version of Google.com (google.ru). If you do not know, Google.com ends up being Google.[country code] within many countries. For example, Google in China is hosted at google.ch (when it is not shut down by the Chinese government) and Google in Canada is hosted at google.ca. Google.ru is for Russia.
The phisher found a redirect at Google Russia that could be abused. It was: https://www[.]google[.]ru/#btnI&q=%3Ca%3EhOJoXatrCPy%3C[/]a%3E. Anything included after the btnI&q could be used for malicious redirection. The “=%3Ca%3EhOJoXatrCPy%3C[/]a%3E” was UTF-8 encoded and when decoded became <[a]>hOJoXatrCPy<[/a]>. The /a is an HTML attribute known as anchor. In this case, the malicious redirect was telling Google Russia to search for ‘hOJoXatrCPy’. The hackers had created some bogus websites where randomly created ‘hOJoXatrCPy’ was a frequent keyword on the site (and nowhere else since it is gibberish). So, Google Russia pushed the victims to the bogus websites where ‘hOJoXatrCPy’ was the highest “relevant” link for the search terms being provided.
As these three examples showed, the major problem is that all three malicious redirects include URL domain names that pointed to legitimate, non-malicious websites, but which ends up allowing a malicious redirect. The moral of the story is you cannot always trust the domain name, alone, to tell you whether a URL is legit or rogue. On top of that, as shown above, the redirect variables are often intentionally hard to recognize and understand, unless you are a naturally suspicious programmer with a lot of time on your hands. So, what is a regular, busy, person supposed to do?
Solution
First, realize that the vast majority of rogue URLs do not use valid, legitimate brand domain names (e.g., microsoft.com). So, first, always look at the domain name in URL and if it does not point to a valid brand web site address, you can just mark it as suspicious without going further. However, if it does include a valid host domain address, you cannot rely on that one, quick check 100%. You want to investigate the email or site presenting the URL a bit more to get more context on whether the supplied URL ultimately points to a valid final domain or not.
Second, did the URL come from an unexpected email or is it a pop-up? Anything unexpected, should be treated with initial suspicion until ruled out one way or the other. Is the unexpected email asking me to click on a URL? If so, that is a high-risk action. Is the URL or email asking me to download a file or open a document? Either is a super high-risk action. What’s the context for the action? Have you ever been asked to do that particular action before by the source asking to do it? If not, and you are being asked to do something you have never done before, even if you think it comes from a valid requestor, that is a high-risk action request.
If you clicked on the link and instead of going to the legitimate domain, you thought you were going to end up on, you end up somewhere else, then treat it as suspicious. Unfortunately, lots of legitimate websites, services and marketing campaigns do the “bait and switch” on you, handing you off to another legitimate service that handles you. So, you really cannot be sure, even if you end up on a different than expected website, if that alone means a link is legitimate or not.
Again, take the preponderance of evidence. If it is a potentially high-risk action and you have never been asked to do it before, then hesitate and do more research before following the suggested action. Better yet, if it is possible for the scenario, do not follow the suggest link. Instead, go to the main provider’s website and start from there. For example, in the UPS example above, the phisher is claiming a delivery needs to be rescheduled. If this request was real, you would be able to go to the real ups.com and find that same recommended request. If you cannot, it is probably not a valid request. When in doubt, chicken out.
If you really think the suspicious request might be valid, open it up on an isolated virtual machine setup for just such analysis. Never click on a suspicious link on your work or production computer and hope for the best. Hope does not prevent malicious hackers. Hope does not prevent ransomware. Hope does not prevent phishing. But a little investigation and a little skepticism can.
Always take the preponderance of evidence when investigating and email or suggested link. Domain name alone is not enough. And watch out for those malicious redirects. They are not super common, but they do exist. Continue to fight the good fight!




